名江蘇教育黃頁新浪微博") 新浪微博
新浪微博

江蘇教育信息
綜合發(fā)布查詢平臺(tái)
江蘇教育信息
綜合發(fā)布查詢平臺(tái)
平安校園")
名-南京網(wǎng)絡(luò)教育-教育培訓(xùn)--江蘇教育黃頁")
手機(jī)套餐優(yōu)惠多多")

員考試 PHP教程 自考 注冊(cè)會(huì)計(jì)師 會(huì)計(jì)證 統(tǒng)統(tǒng)免費(fèi)下")
?12月14日消息,據(jù)華中科技大學(xué)消息,近日,華中科技大學(xué)軟件學(xué)院白翔教授領(lǐng)銜的VLRLab團(tuán)隊(duì)發(fā)布了多模態(tài)大模型——“Monkey”。該模型號(hào)稱能夠?qū)崿F(xiàn)對(duì)世界的“觀察”,對(duì)圖片進(jìn)行深入的問答交流和精確描...
12月14日消息,據(jù)華中科技大學(xué)消息,近日,華中科技大學(xué)軟件學(xué)院白翔教授領(lǐng)銜的VLRLab團(tuán)隊(duì)發(fā)布了多模態(tài)大模型——“Monkey”。該模型號(hào)稱能夠?qū)崿F(xiàn)對(duì)世界的“觀察”,對(duì)圖片進(jìn)行深入的問答交流和精確描述。
▲圖源Monkey項(xiàng)目的GitHub頁面
IT之家注:多模態(tài)大模型是一類可以同時(shí)處理和整合多種感知數(shù)據(jù)(例如文本、圖像、音頻等)的AI架構(gòu)。
據(jù)介紹,Monkey模型在18個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)中表現(xiàn)出色,特別是在圖像描述和視覺問答任務(wù)方面,超越了眾多現(xiàn)有知名的模型如微軟的LLAVA、谷歌的PALM-E、阿里的Mplug-owl等。此外,Monkey在文本密集的問答任務(wù)中顯示出“顯著的優(yōu)勢(shì)”,甚至在某些樣本上超越了業(yè)界公認(rèn)的領(lǐng)先者——OpenAI的多模態(tài)大模型GPT-4V。
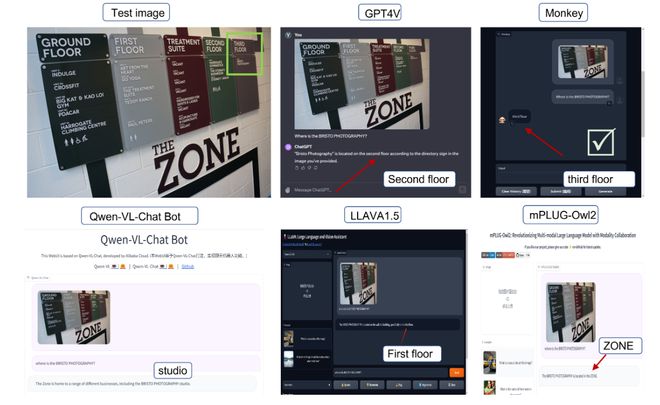
Monkey的一個(gè)顯著特點(diǎn)是“看圖說話”能力。在詳細(xì)描述任務(wù)中,Monkey展現(xiàn)了對(duì)圖像細(xì)節(jié)的感知能力,能夠察覺到其他多模態(tài)大模型所忽略的內(nèi)容。如對(duì)下圖進(jìn)行的文本描述中,Monkey正確地將其識(shí)別為埃菲爾鐵塔的繪畫,并提供了構(gòu)圖和配色方案的詳細(xì)描述。而對(duì)左下角的文字,只有Monkey和GPT-4V能將其準(zhǔn)確地識(shí)別為作者名。

Monkey號(hào)稱能夠利用現(xiàn)有的工具構(gòu)建一種多層級(jí)的描述生成方法,即通過五個(gè)步驟依次對(duì)圖片進(jìn)行整體簡(jiǎn)述、空間定位、模塊化識(shí)別、描述賦分選取和最終總結(jié),此舉可以充分結(jié)合不同工具的特性,提升描述的準(zhǔn)確性和豐富程度。

“一個(gè)個(gè)工具就好比不同的零件,合理的排列組合才能使其發(fā)揮最大作用,”白翔教授說,“我們團(tuán)隊(duì)從2003年開始便從事圖像識(shí)別研究,去年我們又從海外引進(jìn)了專攻多模態(tài)大模型的青年人才,Monkey的最終方案是大家一起反復(fù)討論,嘗試了10余種方案后最終確定的。”白翔教授說。
Monkey的另一亮點(diǎn)是能夠處理分辨率最高1344×896像素的圖像,這是目前其他多模態(tài)大模型所能處理的最大尺寸的6倍,這意味著Monkey能對(duì)更大尺寸的圖片進(jìn)行更準(zhǔn)確、豐富、細(xì)致的描述甚至推理。
Monkey多模態(tài)大模型代碼目前已在GitHub開源。
來源:本文內(nèi)容搜集或轉(zhuǎn)自各大網(wǎng)絡(luò)平臺(tái),并已注明來源、出處,如果轉(zhuǎn)載侵犯您的版權(quán)或非授權(quán)發(fā)布,請(qǐng)聯(lián)系小編,我們會(huì)及時(shí)審核處理。
聲明:江蘇教育黃頁對(duì)文中觀點(diǎn)保持中立,對(duì)所包含內(nèi)容的準(zhǔn)確性、可靠性或者完整性不提供任何明示或暗示的保證,不對(duì)文章觀點(diǎn)負(fù)責(zé),僅作分享之用,文章版權(quán)及插圖屬于原作者。


聯(lián)系郵箱:service#改成@jsedu114.com
地 址:中國(guó)●江蘇
南京市秦淮區(qū)洪武路359號(hào)1506室
Copyright©2013-2025 ?JSedu114 All Rights Reserved. 江蘇教育信息綜合發(fā)布查詢平臺(tái)保留所有權(quán)利
![]() 蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號(hào)-3技術(shù)支持:南京博盛藍(lán)睿網(wǎng)絡(luò)科技有限公司
蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號(hào)-3技術(shù)支持:南京博盛藍(lán)睿網(wǎng)絡(luò)科技有限公司
南京思必達(dá)教育科技有限公司版權(quán)所有 百度統(tǒng)計(jì)





