
絡教育-教育培訓--江蘇教育黃頁")
惠多多")

統(tǒng)免費下")
話不多說,直接上手!場景用的數(shù)據(jù)庫是mysql5.6,下面簡單的介紹下場景課程表create table Course(c_id int PRIMARY KEY,name varchar(10))數(shù)據(jù)100條學生表:create table Student(id int PRIMARY KEY,na...
話不多說,直接上手!
場景
用的數(shù)據(jù)庫是mysql5.6,下面簡單的介紹下場景
課程表
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)
數(shù)據(jù)100條
學生表:
create table Student(
id int PRIMARY KEY,
name varchar(10)
)
數(shù)據(jù)70000條
學生成績表SC
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)
數(shù)據(jù)70w條
查詢目的:
查找語文考100分的考生
查詢語句:
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )
執(zhí)行時間:30248.271s
為什么這么慢?先來查看下查詢計劃:
EXPLAIN
select s.* from Student s where s.s_id in (select s_id from SC sc where sc.c_id = 0 and sc.score = 100 )

發(fā)現(xiàn)沒有用到索引,type全是ALL,那么首先想到的就是建立一個索引,建立索引的字段當然是在where條件的字段。
先給sc表的c_id和score建個索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再次執(zhí)行上述查詢語句,時間為: 1.054s
快了3w多倍,大大縮短了查詢時間,看來索引能極大程度的提高查詢效率,看來建索引很有必要,很多時候都忘記建索引了,數(shù)據(jù)量小的的時候壓根沒感覺,這優(yōu)化感覺挺爽。
但是1s的時間還是太長了,還能進行優(yōu)化嗎,仔細看執(zhí)行計劃:

查看優(yōu)化后的sql:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)
補充:這里有網(wǎng)友問怎么查看優(yōu)化后的語句
方法如下:
在命令窗口執(zhí)行

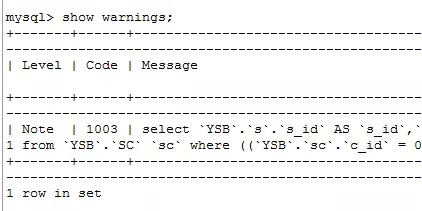
點擊添加圖片描述(最多60個字)
有type=all
按照筆者之前的想法,該sql的執(zhí)行的順序應該是先執(zhí)行子查詢
select s_id from SC sc where sc.c_id = 0 and sc.score = 100
耗時:0.001s
得到如下結(jié)果:
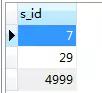
然后再執(zhí)行
select s.* from Student s where s.s_id in(7,29,5000)
耗時:0.001s
這樣就是相當快了啊,Mysql竟然不是先執(zhí)行里層的查詢,而是將sql優(yōu)化成了exists子句,并出現(xiàn)了EPENDENT SUBQUERY,
mysql是先執(zhí)行外層查詢,再執(zhí)行里層的查詢,這樣就要循環(huán)70007*11=770077次。
那么改用連接查詢呢?
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
這里為了重新分析連接查詢的情況,先暫時刪除索引sc_c_id_index,sc_score_index
執(zhí)行時間是:0.057s
效率有所提高,看看執(zhí)行計劃:

這里有連表的情況出現(xiàn),我猜想是不是要給sc表的s_id建立個索引
CREATE index sc_s_id_index on SC(s_id);
show index from SC
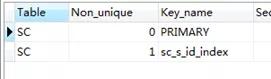
在執(zhí)行連接查詢
時間: 1.076s,竟然時間還變長了,什么原因?查看執(zhí)行計劃:

優(yōu)化后的查詢語句為:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)
貌似是先做的連接查詢,再執(zhí)行的where過濾
回到前面的執(zhí)行計劃:
這里是先做的where過濾,再做連表,執(zhí)行計劃還不是固定的,那么我們先看下標準的sql執(zhí)行順序:

點擊添加圖片描述(最多60個字)
正常情況下是先join再where過濾,但是我們這里的情況,如果先join,將會有70w條數(shù)據(jù)發(fā)送join做操,因此先執(zhí)行where
過濾是明智方案,現(xiàn)在為了排除mysql的查詢優(yōu)化,我自己寫一條優(yōu)化后的sql
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
即先執(zhí)行sc表的過濾,再進行表連接,執(zhí)行時間為:0.054s
和之前沒有建s_id索引的時間差不多
查看執(zhí)行計劃:

先提取sc再連表,這樣效率就高多了,現(xiàn)在的問題是提取sc的時候出現(xiàn)了掃描表,那么現(xiàn)在可以明確需要建立相關索引
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);
再執(zhí)行查詢:
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
執(zhí)行時間為:0.001s,這個時間相當靠譜,快了50倍
執(zhí)行計劃:

我們會看到,先提取sc,再連表,都用到了索引。
那么再來執(zhí)行下sql
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100
執(zhí)行時間0.001s
執(zhí)行計劃:

這里是mysql進行了查詢語句優(yōu)化,先執(zhí)行了where過濾,再執(zhí)行連接操作,且都用到了索引。
總結(jié):
1.mysql嵌套子查詢效率確實比較低
2.可以將其優(yōu)化成連接查詢
3.建立合適的索引
4.學會分析sql執(zhí)行計劃,mysql會對sql進行優(yōu)化,所以分析執(zhí)行計劃很重要
來源:本文內(nèi)容搜集或轉(zhuǎn)自各大網(wǎng)絡平臺,并已注明來源、出處,如果轉(zhuǎn)載侵犯您的版權(quán)或非授權(quán)發(fā)布,請聯(lián)系小編,我們會及時審核處理。
聲明:江蘇教育黃頁對文中觀點保持中立,對所包含內(nèi)容的準確性、可靠性或者完整性不提供任何明示或暗示的保證,不對文章觀點負責,僅作分享之用,文章版權(quán)及插圖屬于原作者。


聯(lián)系郵箱:service#改成@jsedu114.com
地 址:中國●江蘇
南京市秦淮區(qū)洪武路359號1506室
Copyright©2013-2025 ?JSedu114 All Rights Reserved. 江蘇教育信息綜合發(fā)布查詢平臺保留所有權(quán)利
![]() 蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號-3技術支持:南京博盛藍睿網(wǎng)絡科技有限公司
蘇公網(wǎng)安備32010402000125
蘇ICP備14051488號-3技術支持:南京博盛藍睿網(wǎng)絡科技有限公司
南京思必達教育科技有限公司版權(quán)所有 百度統(tǒng)計




 新浪微博
新浪微博


